Video Analysis: Creating Highlights Using Python
Overview
Build your own highlights package in Python using a simple approach
That’s right – learn how automatic highlight generation works without using machine learning or deep learning!
We will implement our own approach to automatic highlight generation using a full-length cricket match
Introduction
I’m a huge cricket fan. I’ve been hooked to the game since I can remember and it still fuels my day-to-day routine. I’m sure a lot of you reading this will be nodding your head!
But ever since I started working full-time, keeping up with all the matches has been a tough nut to crack. I can only catch fleeting finishes to matches rather than the whole package. Or I have to follow along with text commentary – either way, it leaves me wanting more.
So the data scientist in me decided to do something about this. Was there a way I could put my Python skills to use and cut out all the important parts of a match? I essentially wanted to create my own highlights package using Python.
Turns out, I didn’t even need to rely on machine learning or deep learning techniques to do it! And now, I want to share my learning (and code) with our community. Check out the below highlight package. This will give you a taste of what we will be building in this article using a simple speech analysis approach:
Awesome! l will discuss how I made this automatic highlight generation process so you can learn and apply it to any match (or any sport) that you want. Let’s get rolling!
If you’re new to Python or need a quick refresher, make sure you check out our FREE course here.
Table of Contents
A Brief Introduction to Sports Video Highlights
Different Approaches to Automatic Highlight Generation
My Approach to Automatic Highlight Generation
Understanding the Problem Statement
Implementing Automatic Highlight Generation in Python
A Brief Introduction to Sports Video Highlights
We’ve all seen highlights of sports matches at some point. Even if you don’t have an inclination towards sports, you’ll have come across highlights on the television while sitting in a restaurant, lounging in a hotel, etc.
Highlight Generation is the process of extracting the most interesting clips from a sports video.
You can think of this as a classic use case of video summarization. In video summarization, the full-length video is converted into a shorter format such that the most important content is preserved.
In cricket, the full match video contains actions like fours, sixes, wickets, and so on. The unedited version even captures uninteresting events too like defenses, leaves, wide balls, byes, etc.
Highlights, on the other hand, is where the adrenaline-rush kicks in. All the major talking points, like fours, sixes, and wickets – these combine to make the quintessential highlights package.

Extracting highlights manually from a full match video requires a lot of human effort. It is a time-consuming task and unless you work for a video company that does this job day in and day out, you need to find a different approach.
It is also memory-hogging to store a full match video. So, extracting highlights automatically from a full match video saves a lot of time for the creator as well as the user. And that is what we will discuss in this article.
Different Approaches to Highlight Generation
There are different ways we can generate highlights, apart from the manual approach. Two common approaches we can use are – Natural Language Processing (NLP) and Computer Vision. Let’s briefly discuss how they work before we jump to my approach.
Natural Language Processing (NLP) based approach
Think about this for a moment before you look at the steps below. How can you use NLP or a text-based approach to extract the important bits from a cricket match?
Here is a step-by-step procedure:
Extract the audio from an input video
Transcribe the audio to text
Apply Extractive based Summarization techniques on text to identify the most important phrases
Extract the clips of corresponding important phrases to generate highlights
Computer Vision-based approach
This computer vision-based approach will come across as quite intuitive. Computer vision is, after all, the field where we train our machines to look at images and videos. So one way to generate highlights using computer vision is to track the scorecard continuously and extract clips only when there is a four, six or a wicket.
Can you think of any other approaches using either of these techniques? Let me know in the comments section below – I’m very interested in hearing your ideas.
My Approach to Automatic Highlight Generation
AT this point, you might be wondering – we just spoke about two sub-fields of machine learning and deep learning. But the article heading and introduction suggest that we won’t be using these two fields. So can we really generate highlights without building models? Yes!
“Not every problem requires Deep Learning and Machine Learning. Most of the problems can be solved with a thorough understanding of the domain and the data.” – Sunil Ray
I will discuss the concept of automatic highlight generation using Simple Speech Analysis. Let’s discuss a few terminologies before moving on to the ultimate approach.
What is Short Time Energy?
An audio signal can be analyzed in the time or frequency domain. In the time domain, an audio signal is analyzed with respect to the time component, whereas in the frequency domain, it is analyzed with respect to the frequency component:
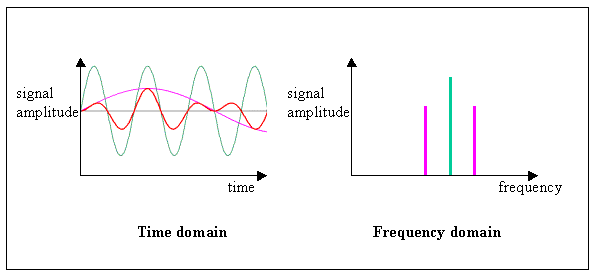
The energy or power of an audio signal refers to the loudness of the sound. It is computed by the sum of the square of the amplitude of an audio signal in the time domain. When energy is computed for a chunk of an entire audio signal, then it is known as Short Time Energy.
The basic idea behind the solution is that in most sports, whenever an interesting event occurs, there is an increase in the commentator’s voice as well as the spectators’.
Let’s take cricket for example. Whenever a batsman hits a boundary or a bowler takes a wicket, there is a rise in the commentator’s voice. The ground swells with the sound of the spectators cheering. We can use these changes in audio to capture interesting moments from a video.
Here is the step-by-step process:
Input the full match video
Extract the audio
Break the audio into chunks
Compute short-time energy of every chunk
Classify every chunk as excitement or not (based on a threshold value)
Merge all the excitement-clips to form the video highlights

Understanding the Problem Statement
Cricket is the most famous sport in India and played in almost all parts of the country. So, being a die-hard cricket fan, I decided to automate the process of highlights extraction from a full match cricket video. Nevertheless, the same idea can be applied to other sports as well.
For this article, I have considered only the first 6 overs (PowerPlay) of the semi-final match between India and Australia at the T20 World Cup in 2007. You can watch the full match on YouTube here and download the video for the first six overs from here.
Automatic Highlight Generation in Python
I have extracted the audio from the video with the help of a software called WavePad Audio Editor. You can download the audio clip from here.
filename='powerplay.wav' import librosa x, sr = librosa.load(filename,sr=16000)
view rawread.py hosted with ❤ by GitHub
We can get the duration of the audio clip in minutes using the code below:
int(librosa.get_duration(x, sr)/60)
view rawduration.py hosted with ❤ by GitHub
Now, we will break the audio into chunks of 5 seconds each since we are interested in finding out whether a particular audio chunk contains a rise in the audio voice:
max_slice=5 window_length = max_slice * sr
view rawwindow.py hosted with ❤ by GitHub
Let us listen to one of the audio chunks:
import IPython.display as ipd a=x[21*window_length:22*window_length] ipd.Audio(a, rate=sr)
view rawlisten.py hosted with ❤ by GitHub
Compute the energy for the chunk:
energy = sum(abs(a**2))print(energy)
view rawenergy.py hosted with ❤ by GitHub
Visualize the chunk in the time-series domain:
import matplotlib.pyplot as plt fig = plt.figure(figsize=(14, 8)) ax1 = fig.add_subplot(211) ax1.set_xlabel('time') ax1.set_ylabel('Amplitude') ax1.plot(a)
view rawviz.py hosted with ❤ by GitHub

As we can see, the amplitude of a signal is varying with respect to time. Next, compute the Short Time Energy for every chunk:
import numpy as npenergy = np.array([sum(abs(x[i:i+window_length]**2)) for i in range(0, len(x), window_length)])
view rawste.py hosted with ❤ by GitHub
Let us understand the Short Time Energy distribution of the chunks:
import matplotlib.pyplot as plt plt.hist(energy) plt.show()
view rawdistribution.py hosted with ❤ by GitHub

The energy distribution is right-skewed as we can see in the above plot. We will choose the extreme value as the threshold since we are interested in the clips only when the commentator’s speech and spectators cheers are high.
Here, I am considering the threshold to be 12,000 as it lies on the tail of the distribution. Feel free to experiment with different values and see what result you get.
import pandas as pddf=pd.DataFrame(columns=['energy','start','end'])thresh=12000row_index=0for i in range(len(energy)): value=energy[i] if(value>=thresh): i=np.where(energy == value)[0] df.loc[row_index,'energy']=value df.loc[row_index,'start']=i[0] * 5 df.loc[row_index,'end']=(i[0]+1) * 5 row_index= row_index + 1
view rawexcitement.py hosted with ❤ by GitHub
Merge consecutive time intervals of audio clips into one:
temp=[]i=0j=0n=len(df) - 2m=len(df) - 1while(i<=n): j=i+1 while(j<=m): if(df['end'][i] == df['start'][j]): df.loc[i,'end'] = df.loc[j,'end'] temp.append(j) j=j+1 else: i=j break df.drop(temp,axis=0,inplace=True)
view rawhighlight.py hosted with ❤ by GitHub

Extract the video within a particular time interval to form highlights. Remember – Since the commentator’s speech and spectators’ cheers increase only after the batsman has played a shot, I am considering only five seconds post every excitement clip:
from moviepy.video.io.ffmpeg_tools import ffmpeg_extract_subclipstart=np.array(df['start'])end=np.array(df['end'])for i in range(len(df)): if(i!=0): start_lim = start[i] - 5 else: start_lim = start[i] end_lim = end[i] filename="highlight" + str(i+1) + ".mp4" ffmpeg_extract_subclip("powerplay.mp4",start_lim,end_lim,targetname=filename)
view rawfinal.py hosted with ❤ by GitHub
I have used online editors to merge all the extracted clips to form a single video. Here are the highlights generated from the PowerPlay using a simple speech analysis approach:
Congratulations on making it this far and generating your own highlight package! Go ahead and apply this technique to any match or sport you want. It might appear straightforward but it’s such a powerful approach.
End Notes
The key takeaways from the article – have a thorough understanding of the domain as well as the data before getting into the model building process since it drives us to a better solution in most of the problems.
In this article, we have seen how to automate the process of highlight extraction from a full match sports video using simple speech analysis. I would recommend you to experiment in different sports too.



Comments
Post a Comment
Please Share Your Views